Pemrosesan Bahasa Alami (NLP) dan Generasi Bahasa Alami (NLG)
David A. Teich Kontributor Senior
Shutterstock
Salah satu keluhan terbesar saya tentang terminologi di industri adalah klaim bahwa data dari percakapan adalah "data tidak terstruktur". Itu omong kosong. Lagi pula, bagaimana orang berkomunikasi, baik dengan suara atau dalam bahasa tertulis, jika tidak ada struktur yang membantu makna? Sintaksis adalah struktur bahasa, dan jelas membantu dalam mendefinisikan semantik, atau makna komunikasi. Untuk memahami bagaimana komputer meningkat dengan cepat, penting untuk melihat bagaimana bahasa alami berbeda dari apa yang sebelumnya diproses oleh komputer.
Dari model penyimpanan data sekuensial flat file ke database relasional (RDBMS), ada sejarah panjang dekade data terstruktur secara kaku. Bagi orang-orang yang terbiasa dengan format seperti itu, bahasa tampaknya sangat tidak terstruktur, yang menyebabkan penggunaan istilah yang salah. Pesatnya pertumbuhan berbasis cloud, teks dan suara, membuat banyak orang bingung dalam dunia basis data tradisional. Namun, sudah saatnya untuk berhenti merujuk ke data yang tidak terstruktur. Frasa lain yang lebih akurat adalah informasi yang terstruktur secara longgar (atau data, jika orang ingin menjadi kurang akurat tetapi lebih nyaman).
Sebagai perbandingan, kecerdasan buatan (AI) telah difokuskan pada meniru pemikiran manusia, komunikasi, dan tindakan. Hampir sejak awal disiplin AI, para peneliti telah tertarik pada bagaimana manusia berkomunikasi. Itu telah menyebabkan dua disiplin ilmu tumpang tindih pemrosesan bahasa alami (NLP) dan generasi bahasa alami (NLG).
Sintaks dan Semantik
Keterbatasan teknologi komputasi sebelumnya berarti bahwa banyak pekerjaan asli dalam AI pada bahasa dilakukan melalui sistem pakar. Tugasnya adalah memahami bahasa dengan mendefinisikan aturan yang dieksekusi oleh sistem. Masalahnya adalah bahwa aturan-aturan itu difokuskan hampir hanya pada sintaks. Sementara itu bisa menyelesaikan banyak masalah, bahasa yang cair dan makna semantik tidak selalu ditemukan dalam sintaksis, dan terkadang sintaksis lebih sulit untuk dideteksi daripada yang diharapkan. Salah satu contoh paling lucu namun relevan dari perpaduan antara sintaksis dan semantik adalah dalam membantu komputer memahami makna yang berbeda dari dua kalimat berikut:
Today In: Inovasi
Waktu berlalu seperti dan panah.
Buah terbang seperti pisang.
Dipromosikan
BRANDVOICE Jepang
| Program berbayar
Bagaimana Kyoto Membangun Kembali Sendiri Sebagai Pembangkit Tenaga Nanotek Dan Regeneratif
BRANDVOICE Civic Nation
| Program berbayar
Membangun Hubungan, Menjelajahi Peluang, Mempersiapkan Diri untuk Sukses: Pekerjaan Konselor Sekolah Hari Ini
BRANDVOICE UNICEF USA
| Program berbayar
Bagi Haiti, Kemenangan Adalah Berjuang Dalam Berjuang Melawan Kolera
Semakin banyaknya aturan memperlambat sistem dan tidak mencapai tingkat akurasi yang dibutuhkan dalam percakapan.
Teknologi pada saat itu juga berarti bahwa fokus bahasa adalah bahasa tertulis. Selain itu, lebih mudah untuk membuat output yang benar secara sintaksis daripada membaca cara kita menulis, jadi fokusnya adalah pada kompleksitas NLP sementara NLG sering dibuat sangat sederhana. Itulah sebabnya mengapa mudah untuk mendapatkan sistem pakar untuk gagal dalam Tes Turing, karena cara orang dapat memutarbalikkan bahasa untuk membingungkan sistem dan kaku, respons mesin dasar berarti mudah untuk mengatakan bahwa percakapan itu dengan sistem pakar dan tidak seorang manusia.
Jaringan Saraf Tiruan Memajukan Bahasa Alami
Kemajuan yang dibawa komputasi awan juga membantu pekerjaan bahasa alami. Kekuatan pemrosesan dari cluster komputer dan prosesor berarti bahwa analisis yang lebih kompleks dapat dilakukan jauh lebih cepat. Itu membawa jaringan syaraf tiruan (JST) ke depan dunia pembelajaran mesin. ANN tidak harus secara eksplisit mendefinisikan semua aturan sintaksis dan menautkannya dengan semantik. Dengan membuat lapisan jaringan yang berbeda untuk menganalisis komponen bahasa yang lebih mendasar, programmer kemudian dapat membiarkan sistem belajar dengan contoh, menggunakan volume besar teks dan ucapan. Hal itu menghasilkan NLP dan NLG yang lebih cepat dan lebih akurat.
Di sisi pemrosesan bahasa alami, yang memungkinkan sistem untuk menganalisis data teks dalam jumlah besar dengan lebih cepat. Itu telah menyebabkan kemajuan dalam kapasitas pencarian internet, analisis sentimen layanan pelanggan, dan di berbagai bidang lainnya. Salah satu contohnya adalah dalam perdagangan. Ada sejumlah besar informasi di infrastruktur teknologi pengecer besar mana pun. Berharap mendapatkan ratusan agen merchandising untuk belajar cara menggunakan antarmuka business intelligence (BI) yang kompleks atau semuanya menjadi ahli di pivot tables bukanlah hal yang baru. Perangkat lunak menjadi, sebagaimana dimaksud pada hari-hari di tempat, sebagai perangkat rak - perangkat lunak dibayar tetapi tidak digunakan.
“Merchandiser dapat mengetik permintaan ad-hoc karena mereka memikirkan pertanyaan itu penting untuk kesuksesan bisnis mereka," kata Doug Bordonaro, Kepala Penginjil Data untuk ThoughtSpot. "Pemrosesan bahasa alami sangat penting untuk membantu merchandiser non-teknis menjadi merchandiser daripada Programmer. Salah satu klien Fortune 100 kami sekarang menjalankan lebih dari 10.000 pencarian setiap minggu dan mendapatkan wawasan harian tentang tren penjualan, bermacam-macam keranjang pasar, dan profitabilitas produk. "
Kemajuan juga membantu dalam audio, dalam pengenalan dan respons suara. Bicara lebih informal daripada menulis. Selain itu, perubahan volume dan aksen dapat memiliki efek yang kuat pada pemahaman. Sementara dekade ini telah melihat keuntungan besar dalam memahami suara-suara yang Silicon Valley tahu (terutama, laki-laki Amerika), basis data baru sekarang diperluas untuk memahami variasi bahasa lisan yang lebih luas.
JST juga membantu di bidang generasi bahasa. Walaupun ini terutama kinerja sistem yang memungkinkan respons lebih cepat terhadap bahasa lisan, NLG juga dibantu oleh struktur jaringan saraf yang lebih fleksibel. Gaya bicara yang dihasilkan tidak terbatas pada aturan yang kaku, didorong oleh sintaks, memberikan pengalaman pelanggan yang lebih alami.
Area kunci lain dari NLG adalah dalam suara dan teks yang dapat membantu menjelaskan jenis output lainnya, seperti visualisasi yang terlihat di banyak dashboard BI. "Visualisasi sangat kuat, tetapi tidak cukup," kata David Judge, VP Leonardo, dan Analytics di SAP. “Gambar dan teks bekerja bersama untuk berkomunikasi dengan manajer. Memiliki solusi NLG yang secara dinamis membangun teks untuk membantu pemahaman adalah keuntungan yang kuat. Mereka juga membuka aksesibilitas ke banyak saluran lain di mana visual tidak mungkin atau bagi orang yang tidak bisa menggunakan antarmuka visual. "
Itu Bukan Salah Satu Atau Yang Lain
Kunci untuk memahami NLP dan NLG adalah mereka berpasangan. Sistem yang dapat memahami dan berkomunikasi dalam bahasa yang lebih alami dapat mempercepat proses analisis dan pengambilan keputusan. Orang belajar dalam banyak cara. Kata-kata dan gambar keduanya memiliki tempat di lingkungan analitik bisnis, jadi perkirakan untuk melihat alat bahasa alami menembus lebih jauh ke pasar dalam dua tahun ke depan.
Mengapa NLP penting?
Volume besar data tekstual
Pemrosesan bahasa alami membantu komputer berkomunikasi dengan manusia dalam bahasa mereka sendiri dan mengukur tugas terkait bahasa lainnya. Sebagai contoh, NLP memungkinkan komputer untuk membaca teks, mendengar ucapan, menafsirkannya, mengukur sentimen dan menentukan bagian mana yang penting.
Mesin saat ini dapat menganalisis lebih banyak data berbasis bahasa daripada manusia, tanpa kelelahan dan dengan cara yang konsisten dan tidak memihak. Mempertimbangkan jumlah data tak terstruktur yang mengejutkan yang dihasilkan setiap hari, dari rekam medis ke media sosial, otomatisasi akan menjadi sangat penting untuk sepenuhnya menganalisis data teks dan ucapan secara efisien.
Menyusun sumber data yang sangat tidak terstruktur
Bahasa manusia sangat kompleks dan beragam. Kami mengekspresikan diri dengan cara yang tak terbatas, baik secara lisan maupun tulisan. Tidak hanya ada ratusan bahasa dan dialek, tetapi di dalam setiap bahasa ada seperangkat aturan tata bahasa dan sintaksis, istilah dan bahasa gaul yang unik. Ketika kita menulis, kita sering salah mengeja atau menyingkat kata-kata, atau menghilangkan tanda baca. Ketika kita berbicara, kita memiliki aksen daerah, dan kita bergumam, gagap, dan meminjam istilah-istilah dari bahasa lain.
Sementara pembelajaran yang diawasi dan tidak diawasi, dan khususnya pembelajaran yang mendalam, sekarang banyak digunakan untuk memodelkan bahasa manusia, ada juga kebutuhan untuk pemahaman sintaksis dan semantik dan keahlian domain yang tidak selalu hadir dalam pendekatan pembelajaran mesin ini. NLP penting karena membantu menyelesaikan ambiguitas dalam bahasa dan menambahkan struktur numerik yang berguna pada data untuk banyak aplikasi hilir, seperti pengenalan suara atau analisis teks.
Generasi bahasa alami (NLG) adalah proses perangkat lunak yang mengubah data terstruktur menjadi bahasa alami. Ini dapat digunakan untuk menghasilkan konten bentuk panjang bagi organisasi untuk mengotomatiskan laporan khusus, serta menghasilkan konten khusus untuk web atau aplikasi seluler. Itu juga dapat digunakan untuk menghasilkan uraian singkat teks dalam percakapan interaktif (chatbot) yang bahkan mungkin dibaca oleh sistem text-to-speech.
NLG otomatis dapat dibandingkan dengan proses yang digunakan manusia ketika mereka mengubah ide menjadi tulisan atau ucapan. Ahli psikologi lebih menyukai istilah produksi bahasa untuk proses ini, yang juga dapat dijelaskan dalam istilah matematika, atau dimodelkan dalam komputer untuk penelitian psikologis. Sistem NLG juga dapat dibandingkan dengan penerjemah bahasa komputer buatan, seperti dekompiler atau transpiler, yang juga menghasilkan kode yang dapat dibaca manusia yang dihasilkan dari representasi perantara. Bahasa manusia cenderung jauh lebih kompleks dan memungkinkan ambiguitas dan ragam ekspresi yang jauh lebih banyak daripada bahasa pemrograman, yang menjadikan NLG lebih menantang.
NLG dapat dipandang sebagai kebalikan dari pemahaman bahasa alami: sedangkan dalam pemahaman bahasa alami, sistem perlu memisahkan kalimat input untuk menghasilkan bahasa representasi mesin, dalam NLG sistem perlu membuat keputusan tentang bagaimana memasukkan konsep ke dalam kata-kata. Pertimbangan praktis dalam membangun sistem NLU vs NLG tidak simetris. NLU perlu berurusan dengan input pengguna yang ambigu atau salah, sedangkan ide-ide yang ingin diungkapkan oleh sistem melalui NLG umumnya diketahui dengan tepat. NLG perlu memilih representasi tekstual yang spesifik dan konsisten sendiri dari banyak representasi potensial, sedangkan NLU umumnya mencoba menghasilkan representasi tunggal yang dinormalisasi dari gagasan yang diungkapkan.
NLG telah ada sejak lama [kapan?] Tetapi teknologi NLG komersial baru belakangan ini [kapan?] Tersedia secara luas. Teknik NLG berkisar dari sistem berbasis template sederhana seperti gabungan surat yang menghasilkan surat formulir, hingga sistem yang memiliki pemahaman kompleks tentang tata bahasa manusia. NLG juga dapat dicapai dengan melatih model statistik menggunakan pembelajaran mesin, biasanya pada kumpulan besar teks yang ditulis manusia.
Contoh [sunting]
Pollen Forecast untuk sistem Skotlandia adalah contoh sederhana dari sistem NLG sederhana yang pada dasarnya bisa menjadi templat. Sistem ini mengambil enam angka input, yang memberikan prediksi tingkat serbuk sari di berbagai bagian Skotlandia. Dari angka-angka ini, sistem menghasilkan ringkasan tekstual singkat dari tingkat serbuk sari sebagai hasilnya.
Misalnya, menggunakan data historis untuk 1 Juli 2005, perangkat lunak menghasilkan:
Tingkat serbuk sari rumput untuk hari Jumat telah meningkat dari tingkat sedang hingga tinggi kemarin dengan nilai sekitar 6 hingga 7 di sebagian besar wilayah negara. Namun, di wilayah utara, tingkat serbuk sari akan moderat dengan nilai 4.
Sebaliknya, perkiraan sebenarnya (ditulis oleh ahli meteorologi manusia) dari data ini adalah:
Hitungan serbuk sari diperkirakan akan tetap tinggi di level 6 di atas sebagian besar Skotlandia, dan bahkan level 7 di tenggara. Satu-satunya bantuan adalah di Kepulauan Utara dan jauh di timur laut Skotlandia daratan dengan jumlah serbuk sari tingkat menengah.
Membandingkan keduanya menggambarkan beberapa pilihan yang harus dibuat sistem NLG; ini dibahas lebih lanjut di bawah ini.
SISTEM PAKAR (Expert System) Beberapa pengertian sistem pakar, diantaranya:
·Sistem Pakar adalah merupakan paket perangkat lunak atau paket program komputer yang disediakan sebagai media penasehat atau membantu dalam memecahkan masalah di bidang-bidang tertentu seperti sains, pendidikan, kesehatan, perekayasaan matematika, dan sebagainya.
·Dari wikipedia Sistem Pakar adalah suatu program komputer yang mengandung pengetahuan dari satu atau lebih pakar manusia mengenai suatu bidang spesifik.
·Sistem Pakar adalah Sistem perangkat lunak komputer yang menggunakan ilmu, fakta, dan teknik berpikir dalam pengambilan keputusan untuk menyelesaikan masalah-masalah yang biasanya hanya dapat diselesaikan oleh tenaga ahli yang bersangkutan.
·Sistem Pakar adalah suatu perangkat lunak komputer berisi pengetahuan yang disimpan untuk memecahkan suatu permasalahan dalam suatu bidang spesifik dengan cara hampir sama dengan seorang tenaga ahli. Pengetahuan datang dari satu rangkaian percakapan yang lalu di kembangkan dari beberapa tenaga ahli suatu sistem.. Sistem tersebut menerima pengetahuan yang berisi suatu masalah dari seorang pengguna.
·Sistem Pakar adalah hasil akhir dari seorang Sarjana Science. Untuk membangun suatu sistem yang dapat memecahkan permasalahan yang sudah ditentukan, seorang sarjana akan memulai dengan membaca literatur terkait dengan permasalahan Sebagai pondasi sistem itu. Seorang sarjana pengetahuan kemudian melakukan wawancara ekslusif dengan satu atau lebih tenaga ahli untuk “memperoleh” pengetahuan mereka. yang akhirnya, sarjana pengetahuan tersebut mengorganisir hasil wawancara dan menterjemahkan ke dalam perangkat lunak komputer yang dapat digunakan oleh seseorang yang sama sekali tidak memiliki suatu keahlian.
·Sistem Pakar adalah suatu perangkat lunak komputer yang dirancang untuk memberikan pemecahan masalah suatu tenaga ahli didalam suatu bidang. Sistem Pakar terdiri atas suatu dasar pengetahuan(informasi, heuristik, dll.), mesin kesimpulan(untuk meneliti dasar pengetahuan), dan alat penghubung (input dan output). Cara yang memimpin ke arah pengembangan Sistem Pakar adalah berbeda dari teknik programan konvensional.
·Sistem pakar ialah sistem yang mewakilkan pengetahuan manusia dalam bentuk program komputer dan menggunakan pengetahuan tersebut dalam penyelesaian masalah; mensimulasikan bagaimana pakar menyelesaikan masalah.
·Sistem Pakar adalah program kecerdasan buatan (artificial intelligence) yang menggabungkan basis pengetahuan (knowledge base) dengan mesin inferensi. Basis pengetahuan dalam sistem pakar berupa suatu aturan yang diperoleh dari pengalaman atau dari seorang pakar pada bidang keahlian tertentu. Berdasarkan basis pengetahuan yang ada, digunakan mesin inferensi untuk mengenerate solusi terhadap domain permasalahan yang akan dipecahkan.
Ciri-Ciri Sistem Pakar Sistem pakar yang baik harus memenuhi ciri-ciri sebagai berikut:
·Memiliki informasi yang handal.
·Mudah dimodifikasi.
·Dapat digunakan dalam berbagai jenis komputer.
·Memiliki kemampuan untuk belajar beradaptasi.
Keuntungan Sistem Pakar
1. Memungkinkan orang awam bisa mengerjakan pekerjaan para ahli. 2. Bisa melakukan proses secara berulang secara otomatis. 3. Menyimpan pengetahuan dan keahlian para pakar. 4. Meningkatkan output dan produktivitas.
5. Meningkatkan kualitas. 6. Mampu mengambil dan melestarikan keahlian para pakar 7. Mampu beroperasi dalam lingkungan yang berbahaya. 8. Memiliki kemampuan untuk mengakses pengetahuan. 9. Memiliki reliabilitas. 10.Meningkatkan kepabilitas sistem komputer. 11. Memiliki kemampuan untuk bekerja dengan informasi yang tidak lengkap dan mengandung ketidakpastian. 12. Sebagai media pelengkap dalam penelitian. 13. Meningkatkan kapabilitas dalam penyelesaian masalah. 14. Menghemat waktu dalam pengambilan keputusan. Kelemahan Sistem Pakar
1.Biaya yang diperlukan untuk membuat dan memeliharanya sangat mahal.
2.Sulit dikembangkan. Hal ini tentu saja erat kaitannya dengan ketersediaan pakar di bidangnya.
3.Sistem Pakar tidak 100% bernilai benar.
Kemampuan Sistem Pakar
1.Menjawab berbagai pertanyaan yang menyangkut bidang keahliannya.
2.Bila diperlukan dapat menyajikan asumsi dan alur penalaran yang digunakan untuk sampai ke jawaban yang dikehendaki.
3.Menambah fakta kaidah dan alur penalaran sahih yang baru ke dalam otaknya
Komponen Sistem Pakar 1. Subsistem Penambah Pengetahuan 2. Basis Pengetahuan Basis pengetahuan adalah suatu jenis basis data yang dipergunakan untuk manajemen pengetahuan. Basis data ini menyediakan fasilitas untuk kleksi,organisasi dan pengambilan pengetahuan terkomputerisasi. 3. Mesin Inferensi Mesin inferensi merupakan elemen inti dari sistem intelejensia buatan 4. BlackBoard Blackboard adalah memori/lokasi untuk bekerja dan menyimpan hasil sementara. Biasanya berupa sebuah basis data. 5. Interface 6. Subsistem Penjelasan Subsistem Penjelasan adalah kemampuan untuk menjejak (tracing) bagaimana suatu kesimpulan dapat diambil merupakan hal yang sangat penting untuk transfer pengetahuan dan pemecahan masalah. Komponen subsistem penjelasan harus dapat menyediakannya yang secara interaktif menjawab pertanyaan pengguna , misalnya:
·“Mengapa pertanyaan tersebut anda tanyakan?”
·“Seberapa yakin kesimpulan tersebut diambil?”
·“Mengapa alternatif tersebut ditolak?”
·“Apa yang akan dilakukan untuk mengambil suatu kesimpulan?”
·“Fakta apalagi yang diperlukan untuk mengambil kesimpulan akhir?”
7. Subsistem Penyaring Pengetahuan Seorang pakar mempunyai sistem penghalusan pengetahuan, artinya, mereka bisa menganalisa sendiri performa mereka, belajar dari pengalaman, serta meningkatkan pengetahuannya untuk konsultasi berikutnya. Pada Sistem Pakar, swa-evaluasi ini penting sehingga dapat menganalisa alasan keberhasilan atau kegagalan pengambilan kesimpulan serta memperbaiki basis pengetahuannya. Jenis-Jenis Sistem Pakar · Interpretasi : Menghasilkan deskripsi situasi berdasarkan data sensor. · Prediksi : Memperkirakan akibat yang mungkin dari situasi yang diberikan. · Diagnosis : Menyimpulkan kesalahan sistem berdasarkan gejala (symptoms). · Disain : Menyusun objek-objek berdasarkan kendala. · Planning : Merencanakan tindakan · Monitoring : Membandingkan hasil pengamatan dengan proses perencanaan. · Debugging : Menentukan penyelesaian dari kesalahan sistem. · Reparasi : Melaksanakan rencana perbaikan. · Instruction : Diagnosis, debugging, dan reparasi kelakuan pelajar. · Control : Diagnosis, debugging, dan reparasi kelakuan sistem.
Penerapan sistem Pakar Sistem pakar dapat diterapkan dalam berbagai bidang seperti, sains, pendidikan, kesehatan, dan sebagainya. Contoh dari tulisan mr. Rizal “Sistem integrasi Pola Alir Material & Uang dapat disebut Material Management System (MMS) adalah kelanjutan perkembangan dari sistem integrasi Inventory Control System (ICS). Sistem (MMS) ini dikembangkan atas sistem manual yang sudah teruji berjalan lancar di PT Krakatau Steel, yang karena tuntutan kemajuan teknologi, sistem manual ini perlu ditingkatkan menjadi sistem komputerisasi. Namun didalam penerapannya masih banyak kendala yang dihadapi oleh subsistem-subsistem pendukung MMS yang ada pada masing-masing divisi. Melalui penelitian ini, dikemukakan satu alternatif yang sangat potensial untuk mengatasi kendala yang dialami oleh subsistem pendukungnya, khususnya yang berada di Divisi Perencanaan & Pengendalian Suku Cadang (PPSC). Dalam penelitian ini dibuat sistem pakar yang mampu memberikan penjelasan dan beberapa alternatif penyelesaian soal-soal Pengendalian Suku Cadang, yang meliputi : Identifikasi Material, Sistem Order, Sistem Repairable dan Sistem Spesifik. Pembuatan sistem pakar ini melalui lima tahapan berikut, yaitu: identifikasi, konseptualisasi, formulasi, implementasi, dan pengujian. Bahasa pemrograman yang digunakan adalah Turbo Prolog, yang cukup ideal dalam menyelesaikan masalah yang undeterministic. Teknik Inferensi yang digunakan adalah backward chaining, proses penelusuran yang digunakan adalah depth first search, dan metoda representasi pengetahuan yang digunakan adalah representasi logika”. Beberapa contoh Sistem Pakar 1. MYCIN : Diagnosa penyakit 2. DENDRAL : Mengidentifikasi struktur molekular campuran yang tak dikenal 3. XCON & XSEL : Membantu konfigurasi sistem komputer besar 4. SOPHIE : Analisis sirkit elektronik 5. Prospector : Digunakan di dalam geologi untuk membantu mencari dan menemukan deposit 6. FOLIO : Menbantu memberikan keutusan bagi seorang manajer dalam hal stok broker dan investasi 7. DELTA : Pemeliharaan lokomotif listrik disel KECERDASAN BUATAN (Artificial Intelligence)
·Artificial Intelligence atau Kecerdasan Buatan adalah suatu sistem informasi yang berhubungan dengan penangkapan, pemodelan dan penyimpanan kecerdasan manusia dalam sebuah sistem teknologi informasi sehingga sistem tersebut memiliki kecerdasan seperti yang dimiliki manusia. Sistem ini dikembangkan untuk mengembangkan metode dan sistem untuk menyelesaikan masalah, biasanya diselesaikan melalui aktifivitas intelektual manusia, misal pengolahan citra, perencanaan, peramalan dan lain-lain, meningkatkan kinerja sistem informasi yang berbasis komputer.
·Kecerdasan buatan didefinisikan sebagai kecerdasan yang ditunjukkan oleh suatu entitas buatan.
·Kecerdasan buatan (Artificial Intelligence) adalah bagian dari ilmu komputer yang mempelajari bagaimana membuat mesin (komputer) dapat melakukan pekerjaan seperti dan sebaik yang dilakukan oleh manusia bahkan bisa lebih baik daripada yang dilakukan manusia.
·Menurut John McCarthy, 1956, AI: untuk mengetahui dan memodelkan proses-proses berpikir manusia dan mendesain mesin agar dapat menirukan perilaku manusia.
Cerdas = memiliki pengetahuan + pengalaman, penalaran (bagaimana membuat keputusan dan mengambil tindakan), moral yang baik Manusia cerdas (pandai) dalam menyelesaikan permasalahan karena manusia mempunyai pengetahuan & pengalaman. Pengetahuan diperoleh dari belajar. Semakin banyak bekal pengetahuan yang dimiliki tentu akan lebih mampu menyelesaikan permasalahan. Tapi bekal pengetahuan saja tidak cukup, manusia juga diberi akal untuk melakukan penalaran,mengambil kesimpulan berdasarkan pengetahuan & pengalaman yang dimiliki. Tanpa memiliki kemampuan untuk menalar dengan baik, manusia dengan segudang pengalaman dan pengetahuan tidak akan dapat menyelesaikan masalah dengan baik. Demikian juga dengan kemampuan menalar yang sangat baik,namun tanpa bekal pengetahuan dan pengalaman yang memadai,manusia juga tidak akan bisa menyelesaikan masalah dengan baik. Agar mesin bisa cerdas (bertindak seperti & sebaik manusia) maka harus diberi bekal pengetahuan & mempunyai kemampuan untuk menalar. Tujuan Kecerdasan buatan:
1.Untuk mengembangkan metode dan sistem untuk menyelesaikan masalah,masalah yang biasa diselesaikan melalui aktifivitas intelektual manusia, misalnya pengolahan citra,perencanaan, peramalan dan lain-lain, meningkatkan kinerja sistem informasi yang berbasis komputer.
2.Untuk meningkatkan pengertian/pemahaman kita pada bagaimana otak manusia bekerja
Keuntungan Kecerdasan Buatan :
1.Kecerdasan buatan lebih bersifat permanen. Kecerdasan alami akan cepat mengalami perubahan. Hal ini dimungkinkan karena sifat manusia yang pelupa. Kecerdasan buatan tidak akan berubah sepanjang sistem komputer dan program tidak mengubahnya.
2.Kecerdasan buatan lebih mudah diduplikasi dan disebarkan. Mentransfer pengetahuan manusia dari satu orang ke orang lain butuh proses dan waktu lama. Disamping itu suatu keahlian tidak akan pernah bisa diduplikasi secara lengkap. Sedangkan jika pengetahuan terletak pada suatu sistem komputer, pengetahuan tersebuat dapat ditransfer atau disalin dengan mudah dan cepat dari satu komputer ke komputer lain
3.Kecerdasan buatan lebih murah dibanding dengan kecerdasan alami. Menyediakan layanan komputer akan lebih mudah dan lebih murah dibanding dengan harus mendatangkan seseorang untuk mengerjakan sejumlah pekerjaan dalam jangka waktu yang sangat lama.
4.Kecerdasan buatan bersifat konsisten. Hal ini disebabkan karena kecerdasan busatan adalah bagian dari teknologi komputer. Sedangkan kecerdasan alami senantiasa berubah-ubah.
5.Kecerdasan buatan dapat didokumentasikan. Keputusan yang dibuat komputer dapat didokumentasikan dengan mudah dengan melacak setiap aktivitas dari sistem tersebut. Kecerdasan alami sangat sulit untuk direproduksi.
6.Kecerdasan buatan dapat mengerjakan pekerjaan lebih cepat dibanding dengan kecerdasan alami
7.Kecerdasan buatan dapat mengerjakan pekerjaan lebih baik dibanding dengan kecerdasan alami.
Komponen Kecerdasan Buatan 1. Basis Pengetahuan Basis Pengetahuan berisi pengetahuan yang dibutuhkan untuk memahami, memformulasi, dan memecahkan masalah. Basis pengetahuan tersusun atas 2 elemen dasar yaitu :
·Fakta, misalnya: situasi, kondisi, dan kenyataan dari permasalahan yang ada, serta teori dalam bidang itu.
·Aturan, yang mengarahkan penggunaan pengetahuan untuk memecahkan masalah yang spesifik dalam bidang yang khusus.
2. Mesin Inferensi Mesin Inferensi (Inference Engine), merupakan otak dari Kecerdasan buatan. Juga dikenal sebagai penerjemah aturan (rule interpreter). Komponen ini berupa program komputer yang menyediakan suatu metodologi untuk memikirkan (reasoning) dan memformulasi kesimpulan. Kerja mesin inferensi meliputi :
·Menentukan aturan mana yang akan dipakai
·Menyajikan pertanyaan kepada pemakai ketika diperlukan.
·Menambahkan jawaban ke dalam memori kecerdasan buatan dan sistem pakar.
·Menyimpulkan fakta baru dari sebuah aturan
·Menambahkan fakta tadi (yang telah diperoleh) ke dalam memori.
3. Interface Kecerdasan buatan dan Sistem Pakar Mengatur komunikasi antara pengguna dan komputer. Komunikasi ini paling baik berupa bahasa alami, biasanya disajikan dalam bentuk tanya-jawab dan kadang ditampilkan dalam bentuk gambar/grafik. Antarmuka yang lebih canggih dilengkapi dengan percakapan (voice communication). Sejarah Artificial Intelligence
·John McCarty
·Logic Theorist
·General Problem Solver (GPS)
Bidang Artificial Intelligence
1.Jaringan Syaraf (Neural Network)
2.Sistem Persepsi (Perceptive System)
3.Belajar (Learning)
4.Robot (Robotics)
5.Perangkat Keras AI (Artificial Intelligence)
6.Pemrosesan Bahasa Alamiah (Natural Language Processing)
Persamaan dan Perbedaan antar Sistem Pakar dengan Kecerdasan Buatan Sistem Pakar juga merupakan bagian dari Artificial Intelligence(AI) atau kecerdasan buatan, dimana letak persamaannya adalah sama-sama untuk mencapai hasil yang maksimal dalam memecahkan masalah, dan perbedaannya adalah sistem pakar mengacu pada si pembuatnya atau seseorang yang ahli dalam suatu bidangnya atau mengacu pada si perancang itu sendiri sebagai objek dalam menyiapkan suatu sistem guna mendapatkan hasil yang maksimal, sedangkan AI mengacu pada jalur atau langkah yang berorientasi pada hardware guna mencapai yang maksimal. Dapat disimpulkan Sistem Pakar merupakan bagian dari AI, dimana selain sistem pakar yang menggunakan AI, ada beberapa yang lain diantarnya games, logika Fuzzy, jaringan saraf tiruan, dan robotika. Kecerdasan buatan merupakan salah satu topik yang disukai penggemar science-fiction, pada film Terminator digambarkan perang manusia melawan mesin, bahkan dalam novel berjudul With Folded Hands karangan Jack Williamson, digambarkan bangsa Humanoids (robot mesin ciptaan manusia) menjajah bangsa manusia dan menggantikan semua peranan manusia.
What is NLG?
Natural Language Generation,as defined byArtificial Intelligence: Natural Language Processing Fundamentals, is the “process of producing meaningful phrases and sentences in the form of natural language.” In its essence, it automatically generates narratives that describe, summarize or explain input structured data in a human-like manner at the speed of thousands of pages per second.
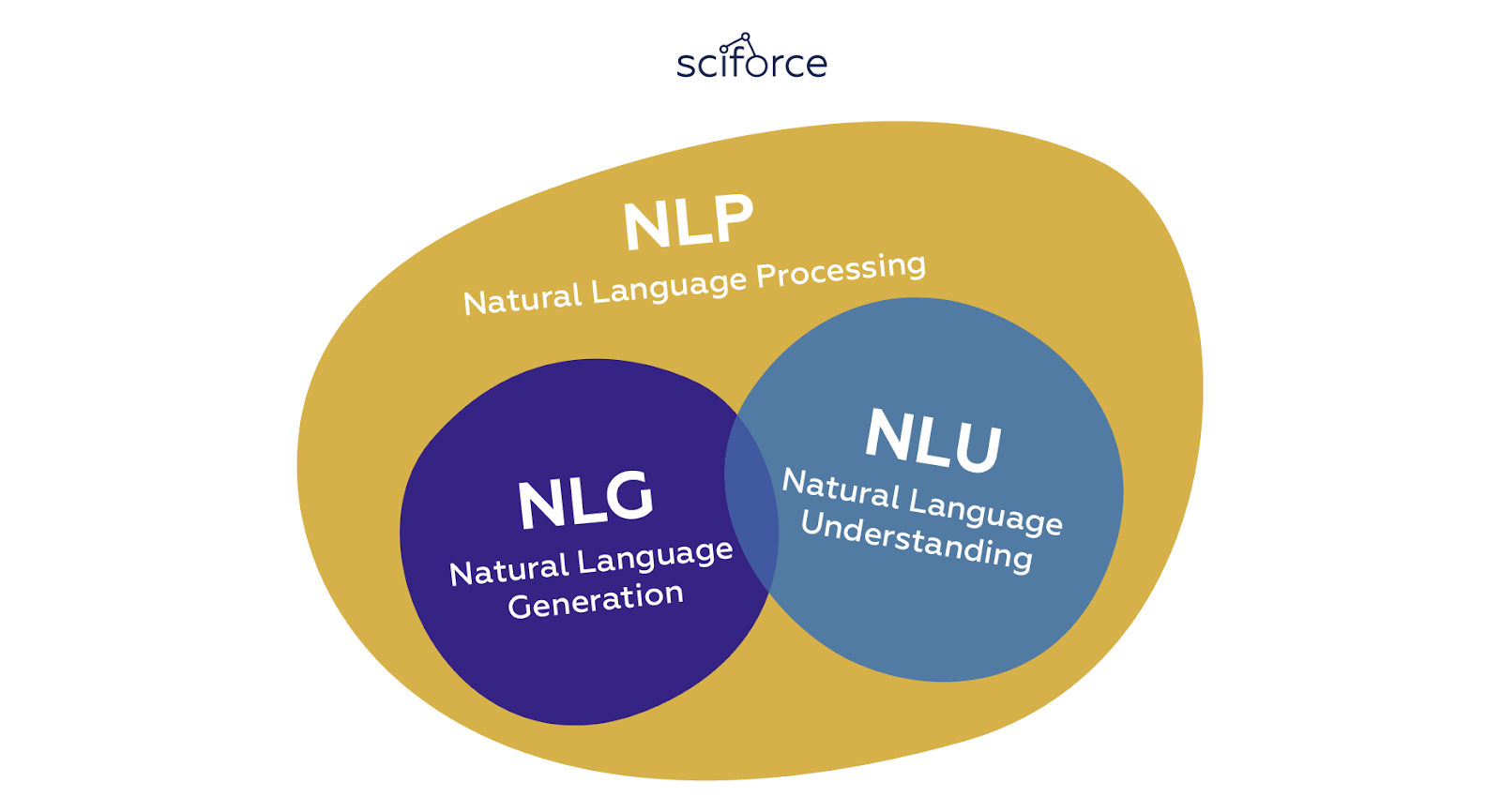
However, while NLG software can write, it can’t read. The part of NLP that reads human language and turns its unstructured data into structured data understandable to computers is called Natural Language Understanding.
In general terms, NLG (Natural Language Generation) and NLU (Natural Language Understanding) are subsections of a more general NLP domain that encompasses all software which interprets or produces human language, in either spoken or written form:
NLU takes up the understanding of the data based on grammar, the context in which it was said and decide on intent and entities.
NLP converts a text into structured data.
NLG generates a text based on structured data.
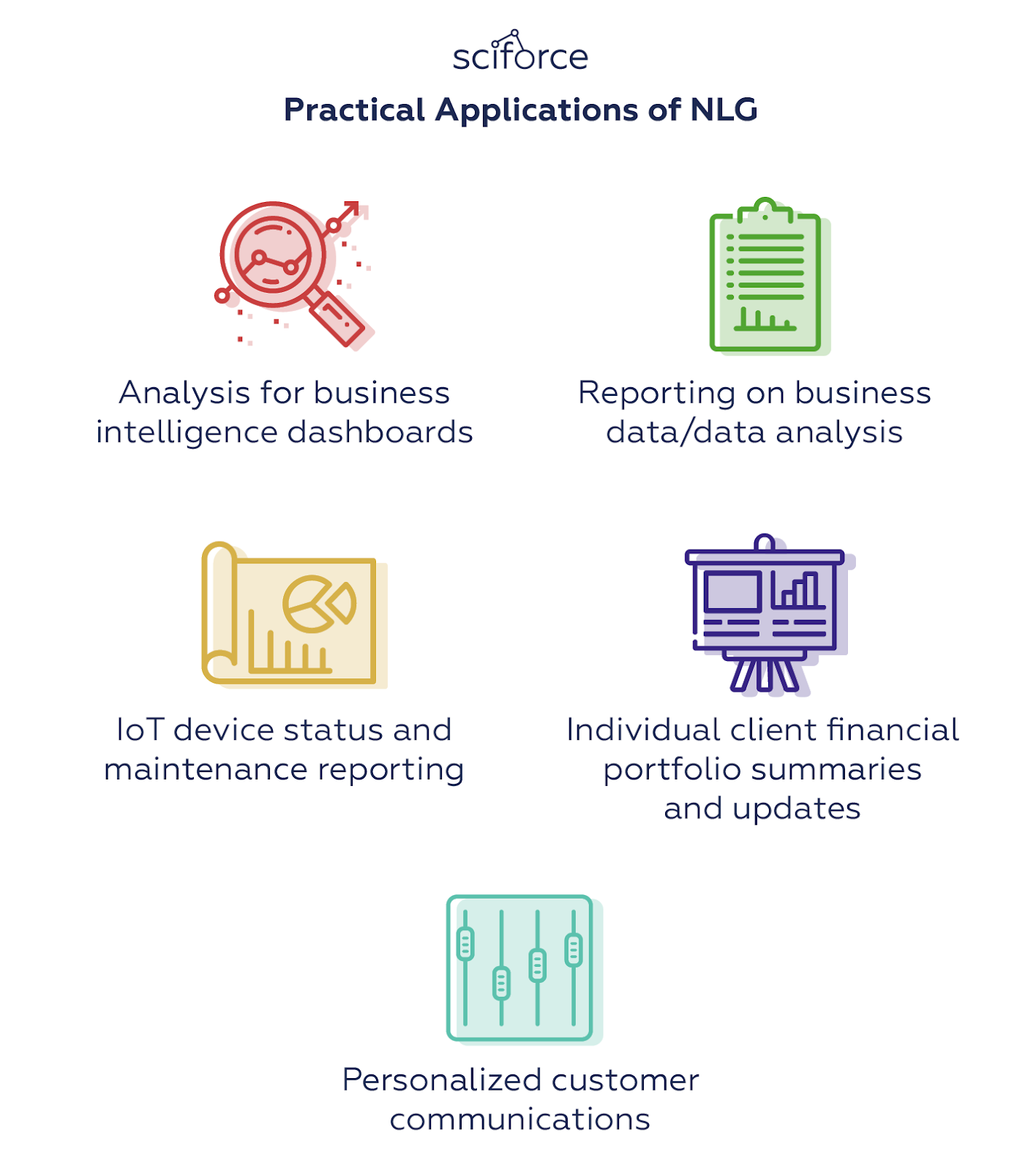
Major applications of NLG
NLG makes data universally understandable making the writing of data-driven financial reports, product descriptions, meeting memos, and more much easier and faster. Ideally, it can take the burden of summarizing the data from analysts to automatically write reports that would be tailored to the audience.The main practical present-day applications of NLG are, therefore, connected with writing analysis or communicating necessary information to customers:
Practical Applications of NLG
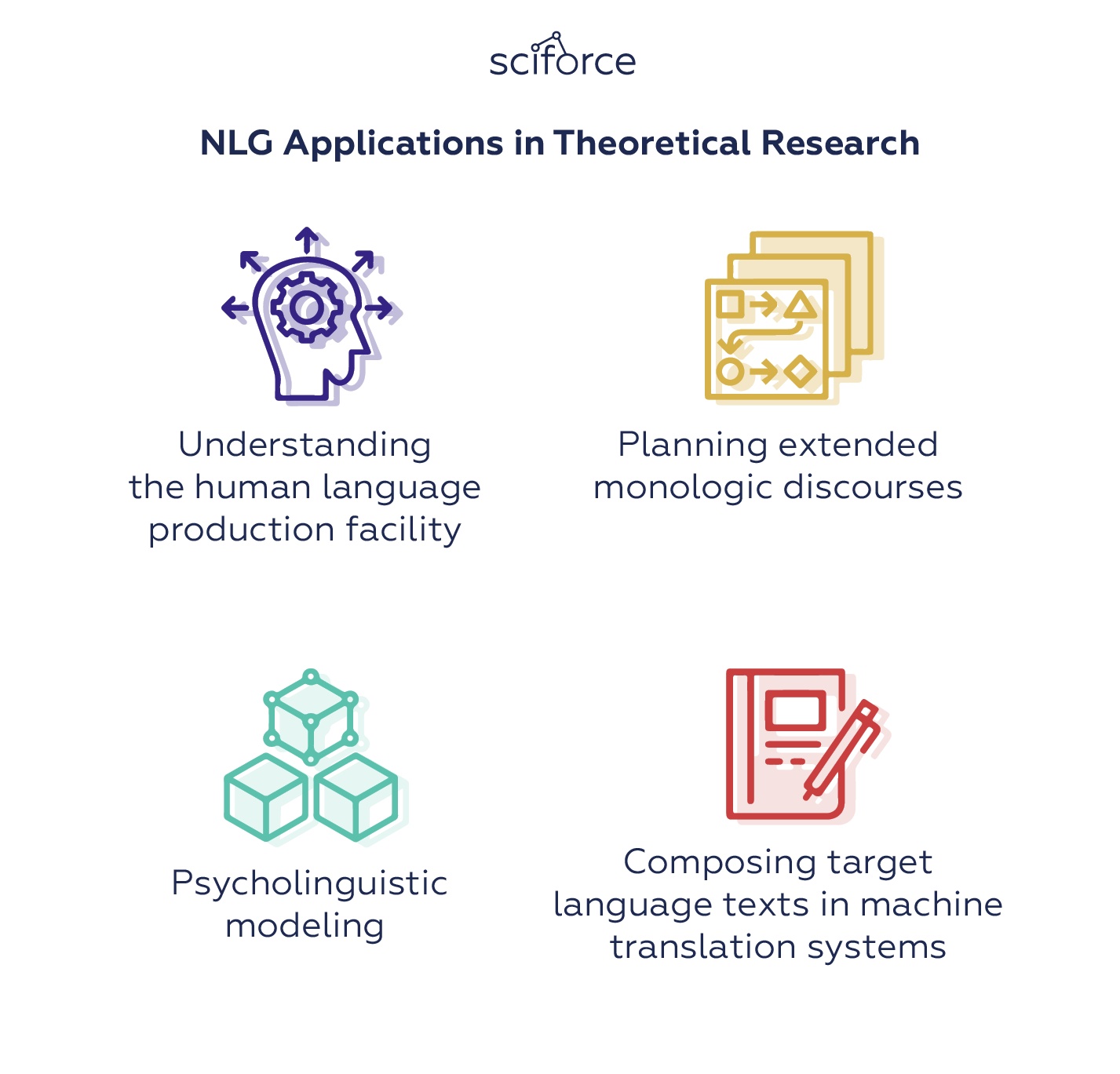
At the same time, NLG has more theoretical applications that make it a valuable tool not only in Computer Science and Engineering, but also in Cognitive Science and Psycholinguistics. These include:
NLG Applications in Theoretical Research
Evolution of NLG Design and Architecture
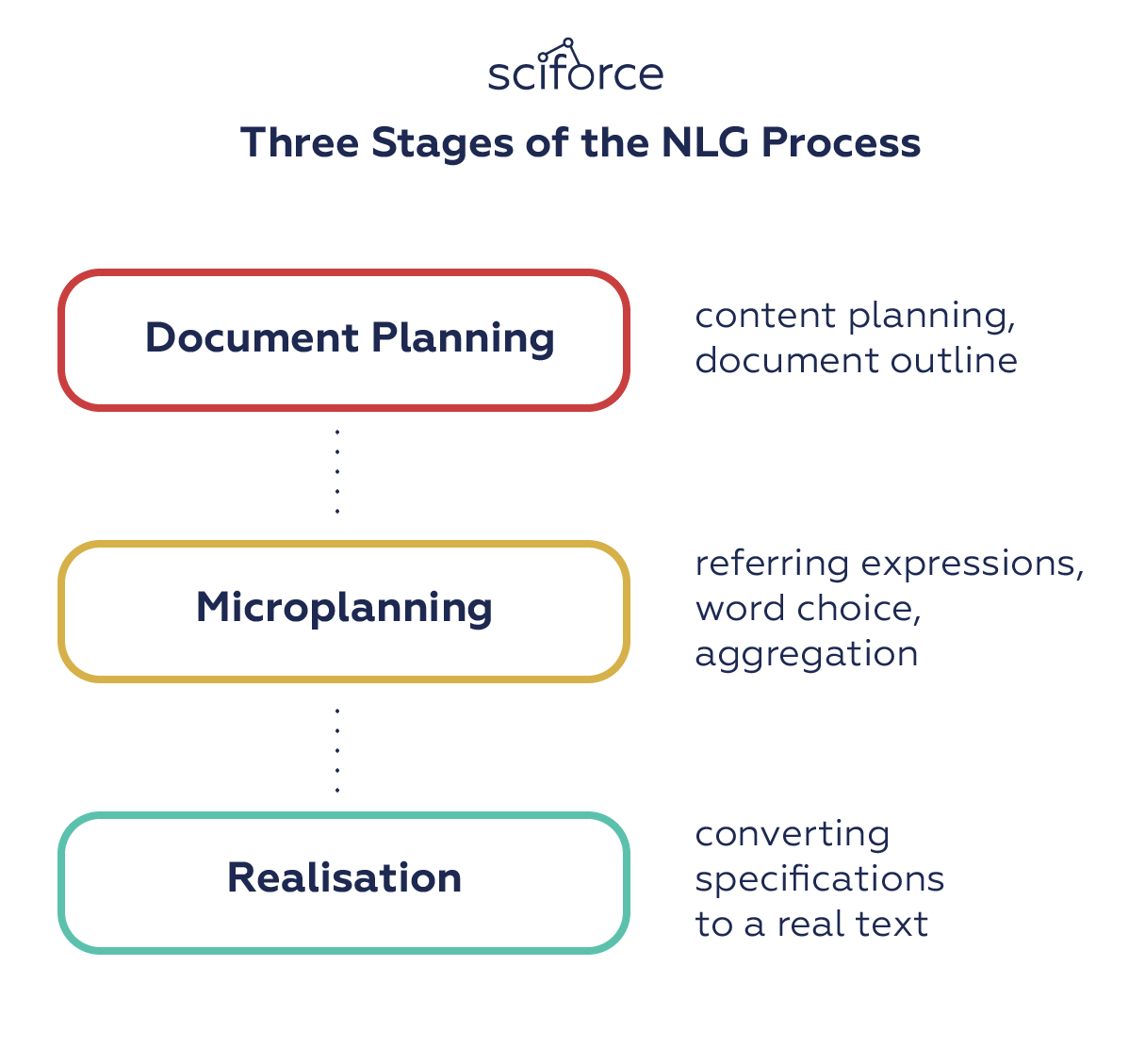
In the attempts to mimic human speech, NLG systems used different methods and tricks to adapt their writing style, tone and structure according to the audience, the context and purpose of the narrative. In 2000 Reiter and Dale pipelined NLG architecture distinguishing three stages in the NLG process:
1. Document planning: deciding what is to be said and creating an abstract document that outlines the structure of the information to be presented.
2. Microplanning: generation of referring expressions, word choice, and aggregation to flesh out the document specifications.
3.Realisation: converting the abstract document specifications to a real text, using domain knowledge about syntax, morphology, etc.
Three Stages of the NLG Process
This pipeline shows the milestones of natural language generation, however, specific steps and approaches, as well as the models used, can vary significantly with the technology development.
There are two major approaches to language generation: using templates and dynamic creation of documents. While only the latter is considered to be “real” NLG, there was a long and multistage way from basic straightforward templates to the state-of-the-art and each new approach expanded functionality and added linguistic capacities:
Simple Gap-Filling Approach
One of the oldest approaches is a simple fill-in-the-gap template system. In texts that have a predefined structure and need just a small amount of data to be filled in, this approach can automatically fill in such gaps with data retrieved from a spreadsheet row, database table entry, etc. In principle, you can vary certain aspects of the text: for example, you can decide whether to spell numbers or leave them as is, this approach is quite limited in its use and is not considered to be “real” NLG.
Scripts or Rules-Producing Text
Basic gap-filling systems were expanded with general-purpose programming constructs via a scripting language or by using business rules. The scripting approach, such as using web templating languages, embeds a template inside a general-purpose scripting language, so it allows for complex conditionals, loops, access to code libraries, etc. Business rule approaches, which are adopted by most document composition tools, work similarly, but focus on writing business rules rather than scripts. Though more powerful than straightforward gap filling, such systems still lack linguistic capabilities and cannot reliably generate complex high-quality texts.
Word-Level Grammatical Functions
A logical development of template-based systems was adding word-level grammatical functions to deal with morphology, morphophonology, and orthography as well as to handle possible exceptions. These functions made it easier to generate grammatically correct texts and to write complex template systems.
Dynamic Sentence Generation
Finally taking a step from template-based approaches to dynamic NLG, this approach dynamically creates sentences from representations of the meaning to be conveyed by the sentence and/or its desired linguistic structure. Dynamic creation means that the system can do sensible things in unusual cases, without needing the developer to explicitly write code for every boundary case. It also allows the system to linguistically “optimise” sentences in a number of ways, including reference, aggregation, ordering, and connectives.
Dynamic Document Creation
While dynamic sentence generation works at a certain “micro-level”, the “macro-writing” task produces a document which is relevant and useful to its readers, and also well-structured as a narrative. How it is done depends on the goal of the text. For example, a piece of persuasive writing may be based on models of argumentation and behavior change to mimic human rhetoric; and a text that summarizes data for business intelligence may be based on an analysis of key factors that influence the decision.
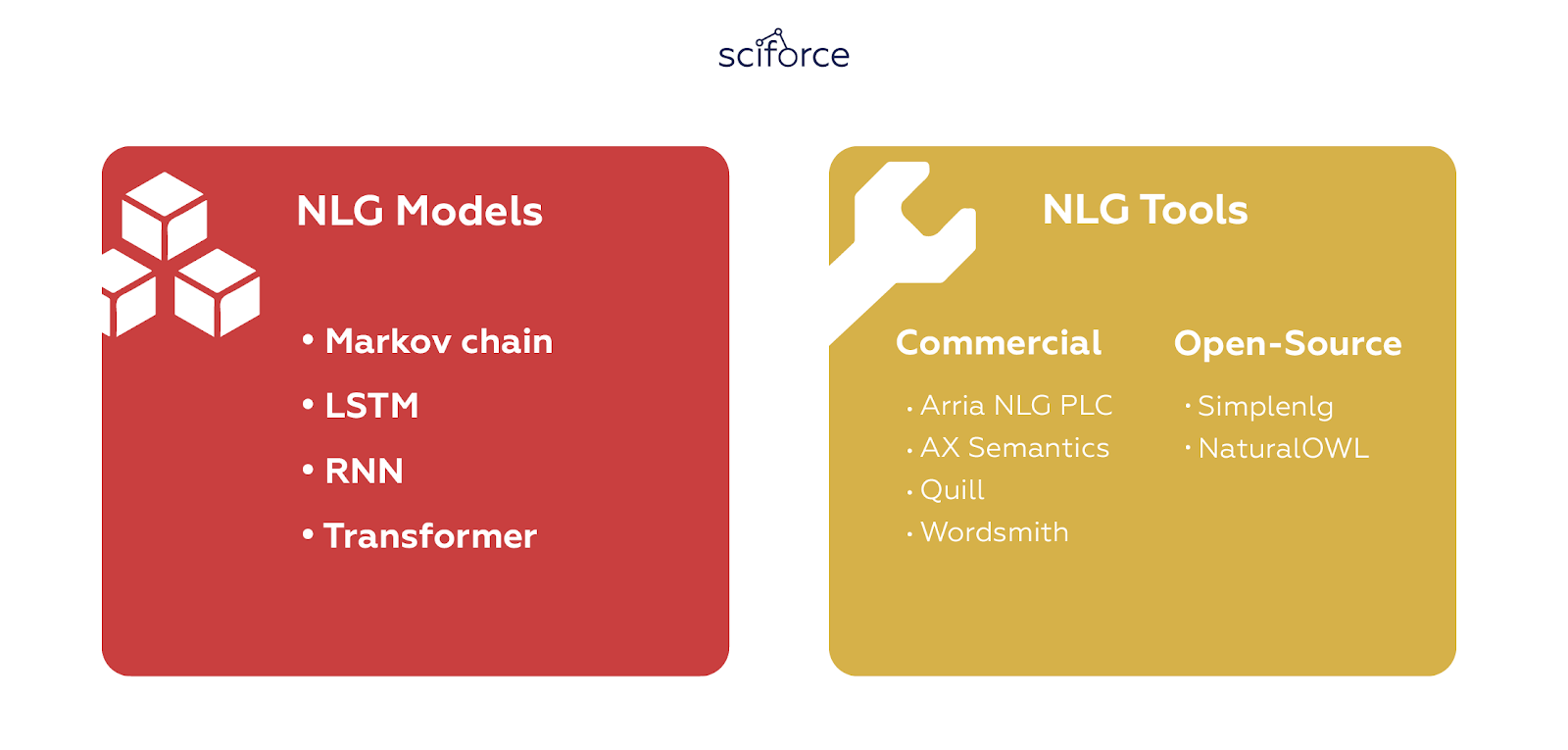
NLG Models
Even after NLG shifted from templates to dynamic generation of sentences, it took the technology years of experimenting to achieve satisfactory results. As a part of NLP and, more generally, AI, natural language generation relies on a number of algorithms that address certain problems of creating human-like texts:
Markov chain
The Markov chain was one of the first algorithms used for language generation. This model predicts the next word in the sentence by using the current word and considering the relationship between each unique word to calculate the probability of the next word. In fact, you have seen them a lot in earlier versions of the smartphone keyboard where they were used to generate suggestions for the next word in the sentence.
Recurrent neural network (RNN)
Neural networks are models that try to mimic the operation of the human brain. RNNs pass each item of the sequence through a feedforward network and use the output of the model as input to the next item in the sequence, allowing the information in the previous step to be stored. In each iteration, the model stores the previous words encountered in its memory and calculates the probability of the next word. For each word in the dictionary, the model assigns a probability based on the previous word, selects the word with the highest probability and stores it in memory. RNN’s “memory” makes this model ideal for language generation because it can remember the background of the conversation at any time. However, as the length of the sequence increases, RNNs cannot store words that were encountered remotely in the sentence and makes predictions based on only the most recent word. Due to this limitation, RNNs are unable to produce coherent long sentences.
LSTM
To address the problem of long-range dependencies, a variant of RNN called Long short-term memory(LSTM) was introduced. Though similar to RNN, LSTM models include a four-layer neural network. The LSTM consists of four parts: the unit, the input door, the output door and the forgotten door. These allow the RNN to remember or forget words at any time interval by adjusting the information flow of the unit. When a period is encountered, the Forgotten Gate recognizes that the context of the sentence may change and can ignore the current unit state information. This allows the network to selectively track only relevant information while also minimizing the disappearing gradient problem, which allows the model to remember information over a longer period of time.
Still, the capacity of the LSTM memory is limited to a few hundred words due to their inherently complex sequential paths from the previous unit to the current unit. The same complexity results in high computational requirements that make LSTM difficult to train or parallelize.
Transformer
A relatively new model was first introduced in the 2017 Google paper “Attention is all you need”, which proposes a new method called “self-attention mechanism.” The Transformer consists of a stack of encoders for processing inputs of any length and another set of decoders to output the generated sentences. In contrast to LSTM, the Transformer performs only a small, constant number of steps, while applying a self-attention mechanism that directly simulates the relationship between all words in a sentence. Unlike previous models, the Transformer uses the representation of all words in context without having to compress all the information into a single fixed-length representation that allows the system to handle longer sentences without the skyrocketing of computational requirements.
One of the most famous examples of the Transformer for language generation is OpenAI, their GPT-2 language model. The model learns to predict the next word in a sentence by focusing on words that were previously seen in the model and related to predicting the next word. A more recent upgrade by Google, the Transformers two-way encoder representation (BERT) provides the most advanced results for various NLP tasks.
NLG Tools
You can see that natural language generation is a complicated task that needs to take into account multiple aspects of language, including its structure, grammar, word usage and perception. Luckily, you probably won’t build the whole NLG system from scratch as the market offers multiple ready-to-use tools, both commercial and open-source.
Commercial NLG Tools
Arria NLG PLC is believed to be one of the global leaders in NLG technologies and tools and can boast the most advanced NLG engine and reports generated by NLG narratives. The company has patented NLG technologies available for use via Arria NLG platform.
AX Semantics: offers eCommerce, journalistic and data reporting (e.g. BI or financial reporting) NLG services for over 100 languages. It is a developer-friendly product that uses AI and machine learning to train the platform’s NLP engine.
Yseop is known for its smart customer experience across platforms like mobile, online or face-to-face. From the NLG perspective, it offers Compose that can be consumed on-premises, in the cloud or as a service, and offers Savvy, a plug-in for Excel and other analytics platforms.Quill by Narrative Science is an NLG platform powered by advanced NLG. Quill converts data to human-intelligent narratives by developing a story, analysing it and extracting the required amount of data from it.
Wordsmith by Automated Insights is an NLG engine that works chiefly in the sphere of advanced template-based approaches. It allows users to convert data into text in any format or scale. Wordsmith also provides a plethora of language options for data conversion.
Open-Source NLG Tools
Simplenlg is probably the most widely used open-source realiser, especially by system-builders. It is an open-source Java API for NLG written by the founder of Arria. It has the least functionality but also is the easiest to use and best documented.
NaturalOWL is an open-source toolkit which can be used to generate descriptions of OWL classes and individuals to configure an NLG framework to specific needs, without doing much programming.
Conclusion
NLG capabilities have become the de facto option as analytical platforms try to democratize data analytics and help anyone understand their data. Close to human narratives automatically explain insights that otherwise could be lost in tables, charts, and graphs via natural language and act as a companion throughout the data discovery process. Besides, NLG coupled with NLP are the core of chatbots and other automated chats and assistants that provide us with everyday support.
As NLG continues to evolve, it will become more diversified and will provide effective communication between us and computers in a natural fashion that many SciFi writers dreamed of in their books.
Demikianlah yang dapat saya sampaikan mengenai materi yang menjadi bahasan ini, tentunya banyak kekurangan dan kelemahan kerena terbatasnya pengetahuan kurangnya rujukan atau referensi yang kami peroleh hubungannya dengan ini. Penulis banyak berharap kepada para pembaca yang budiman memberikan kritik saran yang membangun. Semoga tulisan ini dapat bermanfaat bagi para pembaca khususnya pada penulis.
If you're looking to lose fat then you have to try this brand new custom keto plan.
To design this service, certified nutritionists, fitness couches, and professional chefs have united to develop keto meal plans that are effective, convenient, price-efficient, and fun.
Since their grand opening in early 2019, hundreds of people have already completely transformed their figure and health with the benefits a certified keto plan can provide.
Speaking of benefits:clicking this link, you'll discover 8 scientifically-tested ones offered by the keto plan.
TUGAS PENGANTAR ANIMASI & DESAIN GRAFIS KE- 4.1 JUM'AT, 24 JULI 2020 DOSEN PEMBIMBING : DONIE MARGAVIANTO, SKOM.,MMSI Putri Amalia 17117223 - 3KA20 Sistem Informasi Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Gunadarma ======================================================== Pengertian Vector dan Bitmap Berikut penjelasan mengenai vector dan bitmap dalam desain grafis yang harus Anda ketahui sebelum membuat desain sebuah projek. Bagi orang awam melihat sebuah gambar itu sama saja, namun di dunia design grafis gambar dibagi menjadi 2 jenis tergantung dari tipe gambar dan model gambar. Jika Anda sudah biasa dalam dunia Graphic Design nama vector dan bitmap sudah tidak asing yang biasa digunakan untuk membedakan sebuah gambar. Vector dan bitmap memiliki fungsi, kelebihan, dan kekurangan masing-masing tergantung kebutuhan dari sebuah design grafis. Oleh karena itu, kita akan berbagi sedikit peng...
TUGAS PENGANTAR ANIMASI & DESAIN GRAFIS KE- 3.3 SABTU, 2 MEI 2020 DOSEN PEMBIMBING : DONIE MARGAVIANTO, SKOM.,MMSI Putri Amalia 17117223 - 3KA20 Sistem Informasi Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Gunadarma ======================================================== Storyboard A pa Itu Storyboard? Ilustrasi menggambar storyboard (sumber: techsmith.de) Kalau dilihat sekilas, storyboard terdiri dari sejumlah kotak yang dengan ilustrasi atau gambar. Anggap saja sebagai versi komik dari naskah atau script yang sudah kamu tulis. Terus apa sih pengertian storyboard yang sebenarnya? Storyboard adalah sebuah gambar atau ilustrasi yang digunakan untuk membuat rancangan sketsa yang berisikan rentetan adegan dari video yang akan kamu buat nantinya. Setiap kotak yang tertera di storyboard akan mewakili satu shot adegan. Dari ko...
TUGAS PENGANTAR ANIMASI & DESAIN GRAFIS KE- 3.2 SABTU, 2 MEI 2020 DOSEN PEMBIMBING : DONIE MARGAVIANTO, SKOM.,MMSI Putri Amalia 17117223 - 3KA20 Sistem Informasi Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Gunadarma ======================================================== Storyboard A pa Itu Storyboard? Ilustrasi menggambar storyboard (sumber: techsmith.de) Kalau dilihat sekilas, storyboard terdiri dari sejumlah kotak yang dengan ilustrasi atau gambar. Anggap saja sebagai versi komik dari naskah atau script yang sudah kamu tulis. Terus apa sih pengertian storyboard yang sebenarnya? Storyboard adalah sebuah gambar atau ilustrasi yang digunakan untuk membuat rancangan sketsa yang berisikan rentetan adegan dari video yang akan kamu buat nantinya. Setiap kotak yang tertera di storyboard akan mewakili satu shot adegan. Dari ko...

If you're looking to lose fat then you have to try this brand new custom keto plan.
ReplyDeleteTo design this service, certified nutritionists, fitness couches, and professional chefs have united to develop keto meal plans that are effective, convenient, price-efficient, and fun.
Since their grand opening in early 2019, hundreds of people have already completely transformed their figure and health with the benefits a certified keto plan can provide.
Speaking of benefits: clicking this link, you'll discover 8 scientifically-tested ones offered by the keto plan.